(1)顺序表和链表的区别
| 顺序表 | 链表 | |
|---|---|---|
| 存储空间上 | 物理上一定连续 | 逻辑上连续,物理上不一定连续 |
| 随机访问(用下标访问) | 支持 [ O(1) ] | 不支持 [ O(N) ] |
| 在任意位置插入或者删除元素 | 可能需要挪动元素,效率低 [ O(N) ] | 只需要修改指针指向 |
| 插入 | 动态顺序表,空间不够时需要扩容 (扩容可能造成空间浪费) | 没有容量的概念,按需申请空间 |
| 应用场景 | 元素高效存储、随机访问多 (尾插尾删时间复杂度为O(1)) | 任意位置频繁的插入和删除 |
| 缓存利用率 | 高 | 低 |
(2)缓存利用率
1)存储器层次结构
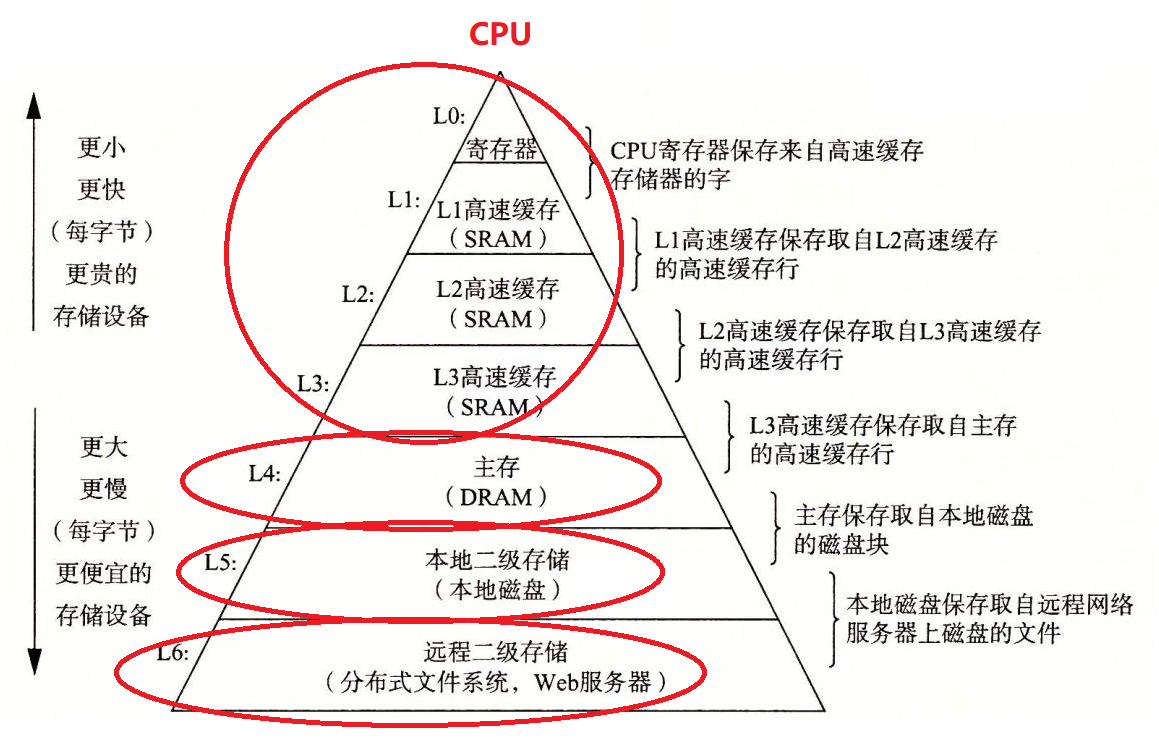
2)CPU和寄存器、高速缓存,以及主存之间的关系
假如我们写了一个程序,实现分别对顺序表和链表上的每个数据+1,这个程序会被编译成指令,由CPU执行指令
CPU运算速度快,读取内存,内存速度跟不上,CPU一般就不会直接访问内存,而是把要访问的数据先加载到缓存体系,如果是小于8byte的数据,直接到寄存器,如果是大的数据会到三级缓存,CPU直接跟缓存交互。
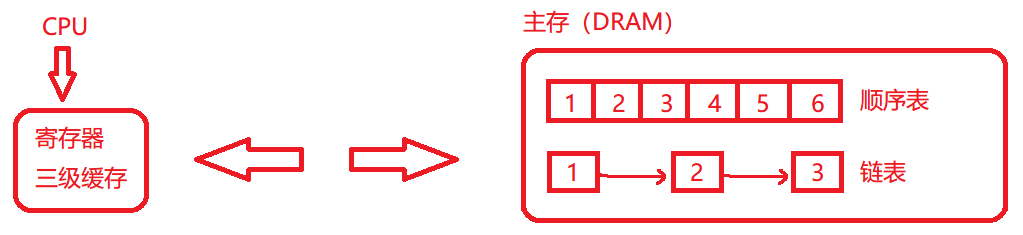
如图:做菜时先会到缓存中去取食材,缓存中没有食材,再去内存那里买……
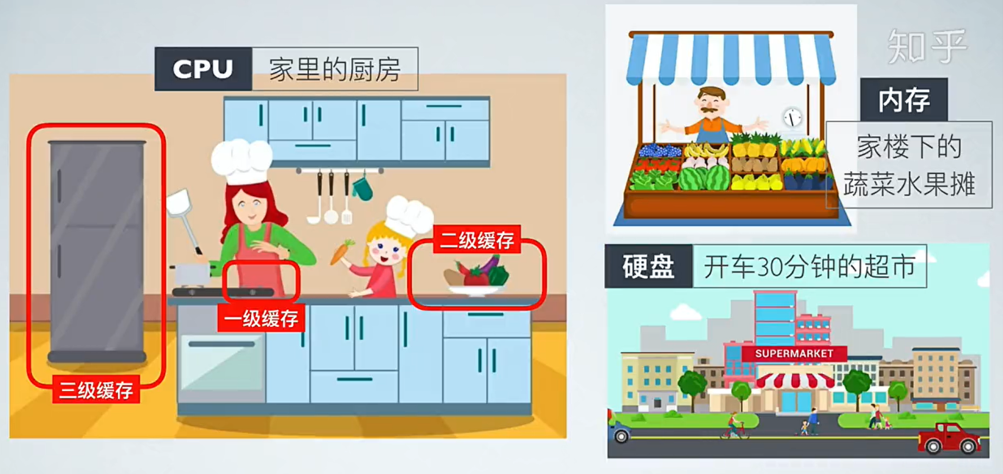
3)缓存利用率
实现分别对顺序表和链表上的每个数据+1,要先读取数据,然后运算,再写回主存
CPU执行指令运算要访问数据,会先去缓存中找有没有这个数据:

顺序表物理地址是连续的,增加了命中率,就不用频繁的从主存中读数据到缓存中,提高了缓存利用率
这就是物理地址连续的优势,所以在现实生活中,很多地方还是推荐用顺序表的
参考文章:
- 与程序员相关的CPU缓存知识 | 酷 壳 - CoolShell